Content:
- Introduction
- Creating a task class
- Analysis Train
- Physics Event Selection
- Event Mixing
- Alien plugin
- Filtering and Calibration * NEW *
Introduction
The analysis framework provide common tools for processing ALICE data in an efficient way. It was designed to take advantage of the existing technologies for parallel computing and provide access to CPU and data to several concurrent analysis modules in the same time (same process).
Analysis modules have no direct dependencies but can communicate processed data via container objects, making the model data oriented. An analysis session is coordinated by a manager class that contains a list of client modules (tasks) as in the picture below. All tasks in the same session are sharing the same event loop (functionality provided by TSelector) and derive from the same base class. Tasks need to implement a set of virtual methods that are called in different stages of processing.
Access to ALICE-specific simulation/reconstruction or analysis data is provided via ESD, AOD and MC event handlers.
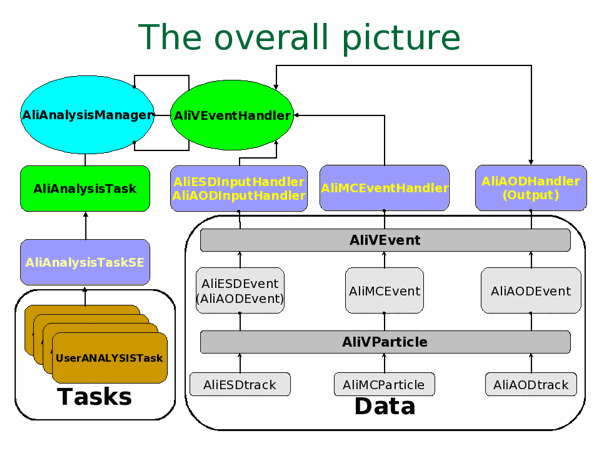
Assembling a user analysis
To run a given analysis algorithm using the analysis framework, one needs to create a root macro that should put together the following components:
- An analysis manager object. This is represented by the singleton class AliAnalysisManager that can be globally accessed via the static method: AliAnalysisManager::GetAnalysisManager().
Creating a task class
To be compliant with the analysis framework, all analysis modules have to implement one class deriving from AliAnalysisTask class. For single event analysis it is most convenient to derive from AliAnalysisTaskSE. This class implements already the default communication with the manager and the data handlers.
Common User Analysis Task:
In most cases, user analysis tasks should derive from AliAnalysisTaskSE. The mandatory methods that have to be implemented are:
-
UserCreateOutputObjects() - Executed once on each worker (machine actually running the analysis code)
-
All objects that will represent the output of the analysis module have to be booked/initialized here (histograms, trees, ...). In case
booking is done by a separate module, this operation has to be delegated from within this method.
- In case some of the task outputs are to be written to a file (most common use case), one has to connect the corresponding output slots to data containers for which the file name is defined explicitely (see comments on Data containers). Writing the output to the file is an automated procedure done after collecting the merged result on the client (local) machine. This is the default behavior which may not be suitable in case of big output objects (big lists of histograms or single huge ones, trees or ntuples). In such case it is mandatory that the outputs get connected to the ouput file upon their booking. For this it is required (by ROOT) that the output file is opened before the creation of the histogram(s) or tree(s). The place to do this in the analysis task is at the beginning of the (User)CreateOutputObjects method (see commented line in the example below).
-
Note: One should never use TFile::Open() to connect data to an output file, but rather the built-in AliAnalysisTask::OpenFile(output_slot). This takes into account both the file name specified at data container level and the different behavior of PROOF and GRID backends.
Example:
void AliAnalysisTaskPt::CreateOutputObjects()
{
// Create histograms
// Called once
fOutputList = new TList();
// OpenFile(0); // Needed in case the object should be connected to the output file (trees)
fHistPt = new TH1F("fHistPt", "P_{T} distribution", 15, 0.1, 3.1);
fHistPt->GetXaxis()->SetTitle("P_{T} (GeV/c)");
fHistPt->GetYaxis()->SetTitle("dN/dP_{T} (c/GeV)");
fHistPt->SetMarkerStyle(kFullCircle);
fOutputList->Add(fHistPt);
}
-
UserExec()
- In this method the user module should implement or call the analysis algorithms per event.
- The input data has the type AliVEvent and can be accessed as fInputEvent data member of the base class, or by using its InputEvent() method. For ESD or AOD specific analysis (depending on the specific input data handler connected to the analysis manager) the pointer has to be cast to AliESDEvent or AliAODEvent repectively.
- The MC information of type AliMCEvent can be accessed as fMCEvent or via the method MCEvent() only in case a MC event handler was connected to the manager
- The output AOD event can be referred as fOutputAOD (or using the getter AODEvent()). A AddBranch() method is provided in the base class AliAnalysisTaskSE to handle user (non-standard) branches in the AOD (see below).
Example:
void AliAnalysisTaskJets::UserExec(Option_t */*option*/)
{
// Execute analysis for current event
//
fJetFinder->GetReader()->SetInputEvent(InputEvent(), AODEvent(), MCEvent());
fJetFinder->ProcessEvent();// Fill control histos
fHistos->FillHistos(AODEvent()->GetJets());
// Post the data (input/output slots #0 already used by the base class)
PostData(1, fListOfHistos);
}
- Non-standard AOD Branches
- Use void AliAnalysisTaskSE::AddAODBranch(const char* cname, void* addobj) in UserCreateOutpuObjects() to add a non-standard branch to the AOD tree. Here, cname is the class name and addobj is the address of the pointer to the object connected to the branch. The name of this object will be used as the name of the branch.
- Example:
void UserCreateOutputObjects()
{- fDiJets = new TClonesArray("AliAODDiJet", 0);
fDiJets->SetName("Dijets");
AddAODBranch("TClonesArray", &fDiJets);
}
- fDiJets = new TClonesArray("AliAODDiJet", 0);
- You might want to write an update AOD-tree, that does not contain the standard-AOD information. In this case the AliAODHandler has to be informed using AliAODHandler::SetCreateNonStandardAOD().
- If you are analysing AOD events as input and you want to write an update AOD that contains the event header you should call in addition AliAODHandler::SetNeedsHeaderReplication(). In this case the event header will be replicated automatically.
Data containers
Data containers are predefined classes of objects within the analysis framework. They are essential for the execution flow of a given analysis, as they not only define the data types that are handled by different tasks but also link a provider task to possible client tasks.
Containers are objects that should never be created by a given analysis task, but by a steering method that will put together a given analysis. Their main role is to formalize a task's input and output data types and to provide placeholders for data that will be actually handled runtime. A task declares the so called data slots of a given TClass type in their constructor. The steering code that creates the analysis manager and the tasks to be used has to create data containers for every slot of the tasks. Note that some containers can be commonly used by different tasks and some are even created by the framework and can be accessed via the analysis manager.
The common input container is created when an input event handler is connected to the manager class and should be used as input container by all tasks that will process data (ESD or AOD) from the main event loop. The common output container is transparent to user analysis and it is used for writing common AOD's to which several different tasks contribute. The latter is created upon connection of an output event handler to the manager.
Data containers should be created via the analysis manager method:
To connect a container to the slot of a task, use:
There are four types of containers defined in AliAnalysisManager.h:
-
kInputContainer - This type of container has to be connected to the task input slot. The common input container should be provided to all first-level tasks (tasks that feed from the main event loop) using AliAnalysisManager::GetCommonInputContainer()
-
kOutputContainer - This type should be connected to the task output slots. If the corresponding output should be written to a file, a file name should be also provided as last argument of the CreateContainer method. The format used can be
, i.e. the data will be written in a given folder. Note that in case a file should be shared as output by several tasks, the analysis manager holds a common file name to be used. This can be retrieved via mgr->GetCommonFileName(). Data slots that are connected to output containers should be published using PostData as explained below. -
kExchangeContainer - This type should be use connected to an output slot that provides data to the input of another task. The corresponding input slot has also to be connected to this container. This container type should be used in all analysis that contain second level tasks.
-
kParamContainer - This type should be used for two purposes: to write out configuration data that was used by the task or post-processed data that is available during the Terminate phase. This type of container should be connected to task output slots and the task should call PostData either in LocalInit or Terminate methods, dependong on the case.
Advanced Task Functionality
In case full functionality of the analysis framework is required, user analysis task class should derive directly from AliAnalysisTask class. Some hints and implementation requirements are presented below.
-
Constructors and input/output slots.
-
All user tasks must have a default constructor and correctly initialize all data members. This is mandatory for any ROOT class requiring I/O and needed in case of running in PROOF mode. In this run mode since the analysis manager with all connected tasks are instantiated on the client but must be streamed to the PROOF master/workers.
-
Note: The default constructor should NOT define input/output slots !
-
Still related to I/O safety, it is recommended that all data members representing just transient pointers to data (like fESD, fAOD, ...) have a //! comment (e.g. not streamed). The same comment is advised for all data members that are to be initialized within CreateOutputObjects() method. Referencing the task itself in the output data structures should be done with caution.
-
All user tasks must have a non-default constructor defining (besides data members) all the requested input and output slots. Any analysis module need to have at least one input slot. The typical slots to be defined are:
-
Example:
MyTask::MyTask(const char *name)
{
// The first input is typically the ESD or AOD chain
DefineInput(0, TChain::Class());
// The first output slot can be the AOD tree if the task may have client tasks using added AOD information
DefineOutput(0, TTree::Class());
// Typically a list of produced histograms
DefineOutput(1, TList::Class());
}
-
NOTE 1: In case of deriving from AliAnalysisTaskSE the input/output slots #0 are already defined so the numbering must start from #1.
-
NOTE 2: If the user module must process AOD information posted by another module it is recommended that the module defines an input slot of type TTree that will be connected at run type to the output of that module.
-
ConnectInputData() - executed once on each worker every time the data at one of the input slots changed. A task calling PostData(#islot, dataPointer) will notify all client tasks of the container connected to output #islot. The ConnectInputData() will be called for all client tasks if the data pointer has changed compared to the previous post.
-
Here typically one gets from the analysis manager the actual pointer to the input tree or branch used in the analysis. Other types of data can be retrieved by casting it to the slot type.
-
Example:
void AliAnalysisTaskPt::ConnectInputData(Option_t *)
{
// Connect ESD or AOD here
// Called on each input data change.TTree* tree = dynamic_cast
(GetInputData(0));
if (!tree) {
Printf("ERROR: Could not read chain from input slot 0");
} else {
// Enable only the needed branches.
tree->SetBranchStatus("fTracks.*", kTRUE);}AliESDInputHandler *esdH = dynamic_cast
(AliAnalysisManager::GetAnalysisManager()->GetInputEventHandler());if (!esdH) Printf("ERROR: Could not get ESDInputHandler");
else fESD = esdH->GetEvent();
}
-
NOTE:The example above correspond to a ESD-only analysis module. It is better (if possible) to design tasks that can be configured for both ESD or AOD input data. In this case the exact type of the input data have to be checked consistently (as example one can look into $ALICE_ROOT/PWG2/SPECTRA/AliAnalysisTaskProtons.h).
-
NOTE: In case the input is AliESDEvent or AliAODEvent it is suggested that the user task to derive from AliAnalysisTaskSE. In this case implementing ConnectInputData() in the user task is NOT NEEDED because the access to the input is provided automatically !
-
Not to be done: A call to MyTask::ConnectInputData() may be triggered from the analysis macro by calling topContainer->SetData(inputTree). To be avoided since at that moment the input handlers are not properly initialized.
-
CreateOutputObjects() - Will replace in this case UserCreateOutputObjects()
-
NOTE: Output objects (histograms or trees) posted to output containers may be written to files or transferred via I/O operations (depending on run mode or configuration). In this case the outputs in memory on the workers will no longer be owned by the user task (but deleted by TFile::Close()). These should not be deleted in the user task destructor.
-
-
Exec() – Event by event processing.
-
In this method the user module should implement or call the analysis algorithms per event. The input data at all input slots or from event handlers is always available within this method.
-
At the and of Exec() (or UserExec() in case of AliAnalysisTaskSE-derived), the user code must post the data to all output slots. This operation will notify all client tasks to be executed at their turn.
-
NOTE: The Exec() method is called for every event so special attention is needed for possible memory leaks that will affect all the train. The memory checker can be activated from the analysis macro via calling: AliAnalysisManager::SetNSysInfo(Long64_t nevents)
-
Besides the mandatory methods, there are some non-mandatory ones that can be implemented by the user module for extra functionality.
-
LocalInit() - called once per task on the client machine where the analysis train is assembled.
-
Here the user task can load and run a configuration macro as in: http://alisoft.cern.ch/viewvc/trunk/JETAN/AliAnalysisTaskJets.cxx?root=AliRoot&view=markup
-
Other alternatives can also be used to configure the task module.
-
-
Notify() - called for every file/tree change. Generally not needed.
-
Terminate() - called once per task on the client machine at the end of the analysis.
-
One should be aware that in PROOF run mode the output objects pointers have to be updated from task output slots since the merged results are sent to the client from PROOF master.
-
Here the user can typically draw histograms.
-
Example:
void AliAnalysisTaskPt::Terminate(Option_t *) {
// Draw some histogram at the end.
if (!gROOT->IsBatch()) {
TCanvas *c1 = new TCanvas("c1","Pt",10,10,800,800);
c1->Divide(2,2,0.005,0.005);
c1->SetFillColor(10);
c1->SetHighLightColor(10);
// Update pointers reading them from the output slot
fList = (TList*)GetOutputData(1);
fHistPt = (TH1F*)fList->At(0);
fHistPx = (TH1F*)fList->At(1);
fHistPy = (TH1F*)fList->At(2);
fHistPz = (TH1F*)fList->At(3);c1->cd(1);
fHistPt->DrawCopy("E");
c1->cd(2)->SetLogy();
fHistPx->DrawCopy("E");
c1->cd(3)->SetLogy();
fHistPy->DrawCopy("E");
c1->cd(4)->SetLogy();
fHistPz->DrawCopy("E");
}
}
Usage of event tags directly in the analysis
Event tags are small objects summarizing event level information. These objects are represented by AliEventTag class and are very useful for efficient event selection. There are 3 ways of using event tags in analysis. The standard procedure uses the AliTagAnalysis utility to produce a chain with selected events lists inside. This is explained in detail in the "Analysis using event tags" section and is mainly performed in 2 stages: a loop on event tags to produce the filtered chain (or xml), then the main analysis loop on the resulting chain.
A new procedure allows accessing the current event tag on the fly and to make dynamic selections. This also allows making cuts on event tag parameters but cannot avoid doing full I/O for all events. The access of the current event tag can be done in the UserExec of the AliAnalysisTaskSE derived user task:
AliEventTag *eventTag = EventTag();if (eventTag) { // Always check the validity of the tag object// perform event tag cuts and return if they don't pass....}
An improved version of this procedure allows loading the relevant ESD or AOD input branches ONLY if the event passes the tag cuts. This implies that the task knows and declares the names of the needed branches. To work in this mode, one has to steer the analysis in the mode:
mgr->SetAutoBranchLoading(kFALSE); // tells the manager not to call chain->GetEntry(currentEntry)
The way to declare which branches are needed by the task (from ESD or AOD) is via the fBranchNames data member that should be filled in the named constructor of the given task:
fBranchNames = "ESD:esdbranch1,esdbranch2,...,esdbranchN AOD:aodbranch1,aodbranch2,..., aodbranchM"; // Tasks not defining this are not allowed to run in a train with no auto branch loading
During analysis, the task should demand explicitly the manager to load the needed branches by calling the method LoadBranches() in its UserExec(), just after the tag-based event selection. Note that extra optimisation can be achieved by calling mgr->LoadBranch(branchName) individually in case selections can still be made on "light" branches before demanding the "heavy" branch of tracks.
Example:
//________________________________________________________________________
AliAnalysisTaskPt::AliAnalysisTaskPt(const char *name)
: AliAnalysisTaskSE(name), fEvent(0), fOutputList(0), fHistPt(0)
{
// Named constructor. Define input and output slots only here.
// Output slot #1 writes into a TH1 container
DefineOutput(1, TList::Class());// Define ESD and AOD branches that are needed here
fBranchNames = "ESD:AliESDRun.,AliESDHeader.,Tracks AOD:header,tracks";
}
//________________________________________________________________________
void AliAnalysisTaskPt::UserExec(Option_t *)
{
// Main loop
// Called for each event
fEvent = InputEvent();
if (!fEvent) {
printf("ERROR: Event not available\n");
return;
}
// Get the tag for the current event and check if it is valid.
const AliEventTag *evTag = EventTag();
Int_t ntracks = 0;
Int_t npions = 0;
if (evTag) {
ntracks = evTag->GetNumOfTracks();
npions = evTag->GetNumOfPions();
// Add a tag-based rejection here
if (npions20) return;
} else {
// Tags are not available, fall back on the normal procedure
LoadBranches();
ntracks = fEvent->GetNumberOfTracks();
}
// Load all requested branches (or individually, if selections can
// still be made based on "light" branches
LoadBranches();// Track loop to fill a pT spectrum
printf("There are %d tracks in this event\n", ntracks);
for (Int_t iTracks = 0; iTracks ntracks; iTracks++) {...
Note: Knowing which branches are needed by a task is not obvious to find as there is no utility telling which data members of the ESD or AOD need to be loaded from file so that all ESD/AOD methods that are called by the task would get valid results. One has to check thorowly all these methods to determine the list of branches. One should ALWAYS check that the results when the task is run without automatic branch loading are the same as in the default mode.
Analysis train
The analysis train is the way to run analysis in the most efficient way over a large part or the full dataset. It is using the AliAnalysisManager framework to optimize CPU/IO ratio, accessing data via a common interface and making use of PROOF and GRID infrastructures.
The train is assembled from a list of modules that are sequentially executed by the common AliAnalysisManager object. All tasks will process the same dataset of input events, share the same event loop and possibly extend the same output AOD with their own information produced in the event loop. The schema is presented below:
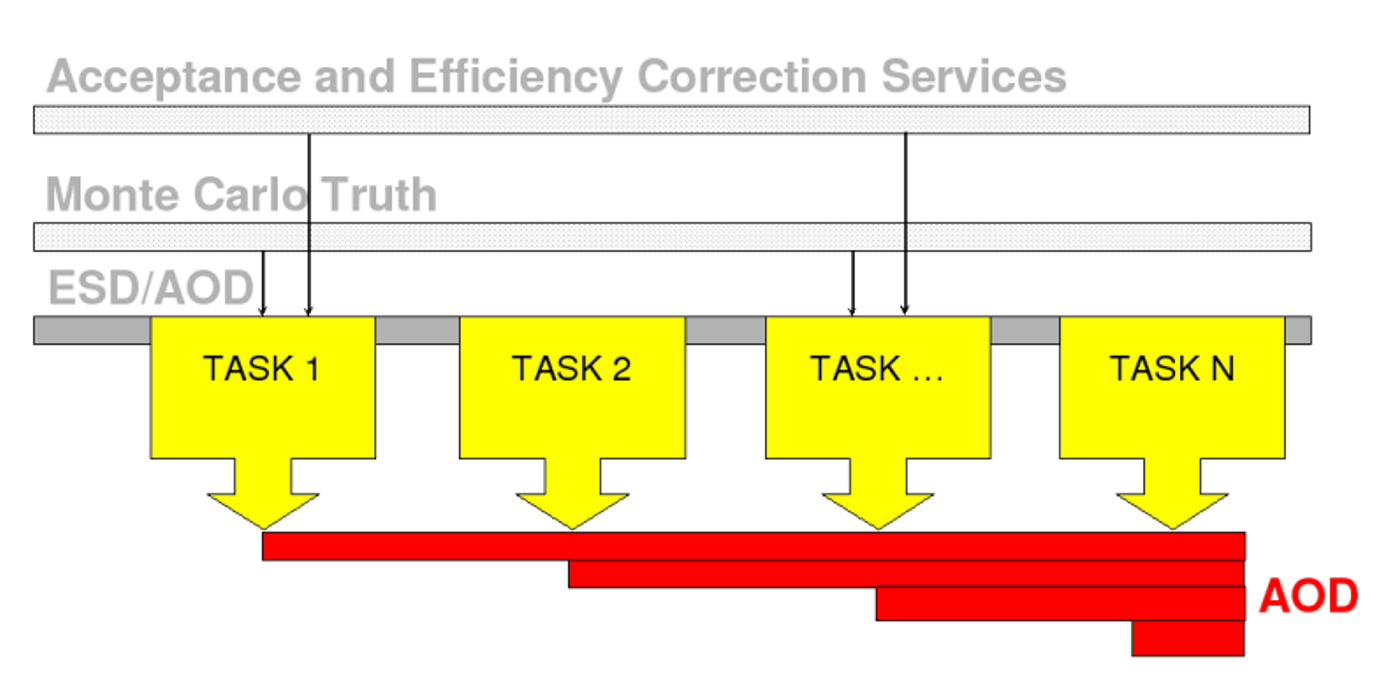
Creating the analysis train
The following components are required to successfully create and run an analysis train:
-
Valid AliRoot libraries or PROOF packages (.par files) reflecting the desired version of the data structures (ESD and AOD), analysis framework and of course user analysis modules. In PROOF run mode .par files are mandatory for testing not deployed development versions of the code. For GRID the usage of .par files is not recommended since a build against a requested AliRoot version that is generally not the one tested on the local machine is likely to fail. Such compilation failures will not be debugged by the core team. For creating a .par file for a package:
cd $ALICE_ROOT
make.par
cp /tmp/.par workdir
-
The required libraries are:
-
libSTEERBase.so - base classes
-
libAOD.so - AOD event structure + related classes
-
libESD.so - ESD event structure + related classes
-
libANALYSIS.so - Analysis framework
-
libANALYSISalice.so - ALICE specific analysis classes
-
libCORRFW - Correction framework
-
-
Several analysis modules are currently tested
-
Loading in memory or uploading the needed packages
-
Local case:
-
gSystem->Load("libTree.so");
gSystem->Load("libGeom.so");
gSystem->Load("libVMC.so");
gSystem->Load(“libPhysics”);// Common packages
gSystem->Load("libSTEERBase.so");
gSystem->Load("libESD.so");
gSystem->Load("libAOD.so");
gSystem->Load("libANALYSIS.so");
gSystem->Load("libANALYSISalice.so");// Analysis-specific
/SPECTRA/AliAnalysisTaskProtons.cxx++");
//SetupPar("JETAN"); // JET analysis
//SetupPar("PWG4Gamma"); // Gamma analysis
//SetupPar("PWG2spectra"); // Proton analysis
...
gSystem->Load("libJETAN.so");
gSystem->Load("libPWG4Gamma.so");
gSystem->Load("libPWG2spectra.so");
...
// A task can be compiled dynamically with AClic, but it is RECCOMENDED to be put in libraries after development
gROOT->ProcessLine(".L $ALICE_ROOT/PWG2
-
PROOF case:
// Reset user processes if CAF if not responding anymore
TProof::Reset("lxb6046");
// One may enable a different ROOT version on CAF
// TProof::Mgr("lxb6046")->ShowROOTVersions();
// TProof::Mgr("lxb6046")->SetROOTVersion("vHEAD_dbg");// Connect to proof
TProof::Open("lxb6046"); // may be username@lxb6046 if user not the same as on local// Clear packages if changing ROOT version on CAF or local
// gProof->ClearPackages();
// Enable proof debugging if needed
// gProof->SetLogLevel(5);
// To debug the train in PROOF mode, type in a root session:
// root[0] TProof::Mgr("lxb6064")->GetSessionLogs()->Display("*",0,10000);// Common packages
// --- Enable the STEERBase Package
gProof->UploadPackage("STEERBase.par");
gProof->EnablePackage("STEERBase");
// --- Enable the ESD Package
gProof->UploadPackage("ESD.par");
gProof->EnablePackage("ESD");
// --- Enable the AOD Package
gProof->UploadPackage("AOD.par");
gProof->EnablePackage("AOD");
// --- Enable the ANALYSIS Package
gProof->UploadPackage("ANALYSIS.par");
gProof->EnablePackage("ANALYSIS");
// --- Enable the ANALYSISalice Package
gProof->UploadPackage("ANALYSISalice.par");
gProof->EnablePackage("ANALYSISalice");// Analysis-specific
// --- Enable the JETAN Package
gProof->UploadPackage("JETAN.par");
gProof->EnablePackage("JETAN");
// --- Enable gamma jet analysis
gProof->UploadPackage("PWG4Gamma.par");
gProof->EnablePackage("PWG4Gamma");
// --- Enable proton analysis
gProof->UploadPackage("PWG2spectra.par");
gProof->EnablePackage("PWG2spectra");// A task can be sent with gProof->Load()
gProof->Load(gSystem->ExpandPathName("$ALICE_ROOT/PWG2/SPECTRA/AliAnalysisTaskProtons.cxx+"));
-
GRID case:
Same as local case, but all the required packages have to be copied in AliEn space together with the jdl file describing the job. All files under InputFile directive have to be copied in the local user space. For other requirements for GRID case (creating XML collection, necessary files) see http://alice-offline.web.cern.ch/Activities/Reconstruction/RunEventTagSystem/index.html
IMPORTANT NOTES: The process of editing the jdl, providing all the required files and keeping consistency of the files is error prone and cannot be supported centrally for all users. Therefore it is highly encouraged that all user analysis are submitted via the AliEn handler plugin, described here. User analysis should mandatory be tested first on local events and in PROOF mode before submitting on large scale in AliEn. The merging of output files is supported only via the AliEn plugin; any merging via the Merge jdl command should be customized by the user who should not rely on centrally-maintained merging macros/jdl's. Users should be aware that the merging part is dependent on the ROOT version and can anyway fail for output types that are scaling with the number of processed events (tree, ntuple,...)
JDL example for the analysis train
Submission of the analysis train is now fully based on the AliEn handler.
Creating the input chain or providing a valid dataset name.
Creating the input chain is dependent on the run mode and on where the data is actually sitting. Simple macros for local analysis are provided to create the input chain from local files (CreateLocalChain.C), files available on CAF (CreateESDChain.C) of files from ALIEN (CreateChain.C).
Instantiating and configuring an analysis manager and the task modules to be run in the train
-
Independent of run mode (local, proof or grid).
-
Creating event handlers (ESD, AOD, MC) and connecting them to the analysis manager.
-
Creating the ESD filter task and configuring the cuts.
-
Creating and configuring the task for each analysis module in the train.
-
Creating all input/output containers required by the analysis modules.
-
Starting the analysis.
Current train status
A fully working example is provided in AliRoot trunk via the macro $ALICE_ROOT/ANALYSIS/macros/AnalysisTrainNew.C. The current tested train wagons contain:
- ESD to AOD filtering tasks (standard ESD filter + MUON filters, Vertexing AOD, Centrality AOD)
- First physics analysis tasks (dNdEta, dNdEtaCorrection and Multiplicity)
- Proton analysis, femtoscopy analysis, CheckV0 , Strangeness analysis flow and resonances (PWG2 SPECTRA)
- D0 analysis train, MUON train, HFE (PWG3)
- Jet analysis (JETAN)
- Particle correlations analysis modules (PWG4)
Result AOD's (and histograms) can be found at the following location: /alice/cern.ch/user/m/mgheata/AODs/300000
The extra libraries needed to run the example are:
-
STEERBase ESD AOD ANALYSIS ANALYSISalice JETAN PWG4PartCorrBase PWG4PartCorrDep PWG2spectra PWG2AOD PWG2femtoscopy PWG2femtoscopyUser PWG2flow PWG3base PWG3muon PWG3vertexingHF CORRFW
The train can be run locally (AnalysisTrain.C), on CAF (AnalysisTrainCAF.C) or in AliEn (submit AnalysisTrain.jdl after copying all necessary files to Alien space and providing a valid global.xml). Please read the README file inside the tarball.
Classes compliant with the analysis framework
NOTE: this table is not complete and will be update as soon as the developers report the correct status
| Group | class | Comment | Input | Output | local | CAF | GRID |
| PWG0 | AlidNdEtaTask | First physics | ESD/MC | Histograms | OK | OK | OK |
| PWG0 | AlidNdEtaCorrectionTask | First physics | ESD/MC | Histograms | OK | OK | OK |
| PWG0 | AliMultiplicityTask | First physics | ESD/MC | Histograms, Ntuple | OK | OK | OK |
| PWG1 | Reconstruction | N/A | N/A | N/A | |||
| PWG2 SPECTRA |
AliAnalysisTaskProtons | p/pbar analysis | ESD/AOD +MC | Histograms, CF containers | OK | OK | OK |
| PWG2 SPECTRA | AliAnalysisTaskCheckCascade | QA for cascades | ESD/AOD | Histograms | OK | OK | OK |
| PWG2 SPECTRA | AliAnalysisTaskCheckPerformanceCascade | Performance study for cascade identification | ESD/AOD +MC | Histograms | OK | OK | OK |
| PWG2 SPECTRA |
AliAnalysisTaskFemto | Femtoscopy | ESD/AOD +MC | Histograms | OK | OK | OK |
| PWG2 SPECTRA |
AliAnalysisTaskCheckV0 | V0 check | ESD/AOD | Histograms | OK | OK | OK |
| PWG2 SPECTRA |
AliAnalysisTaskStrange | Strangeness | ESD/AOD | Histograms | OK | OK | OK |
| PWG2 FLOW |
Fill flow events from AOD/ESD/MC for flow analysis |
ESD/AOD +MC |
transient AliFlowEventSimple QA hists |
OK | OK | OK | |
| PWG2 FLOW | AliAnalysisTaskScalarProduct | Flow analysis using scalar product method | FlowEvent | Histograms | OK | OK | OK |
| PWG2 FLOW | AliAnalysisTaskLeeYangZeros (SUM & PROD) | Flow analysis using LeeYang zeros method | FlowEvent | Histograms | OK | OK | OK |
| PWG2 FLOW | AliAnalysisTaskCumulants | Flow analysis with cumulants method | FlowEvent | Histograms | OK | OK | OK |
| PWG2 FLOW | AliAnalysisTaskQCumulants | Flow analysis with Qcumulants method | FlowEvent | Histograms | OK | OK | OK |
| PWG2 RESONANCES |
AliRsnAnalysisSE | Resonances analysis | ESD +MC | Histograms | OK | OK | OK |
| PWG2 KINK | AliAnalysisTaskKinkESDMC | Kink topology study | ESD +MC | Histograms | OK | OK | OK |
| PWG2 KINK | AliAnalysisTaskKinkResonance | Reco. for resonances with a kaon kink | ESD +MC | Histograms | OK | OK | OK |
| PWG2 KINK | AliResonanceKinkLikeSign | Background computation for resonances with kaon kinks | ESD | Histograms | OK | OK | OK |
| PWG2 EVCHAR | AliAnalysisTaskSPDdNdEta | dN/dEta reco. with SPD | ESD +MC +TrackRefs | Histograms | OK | ? | ? |
| PWG2 UNICOR | AliAnalysisTaskUnicor | Unicor analysis modules | ? | ? | OK | ? | ? |
| PWG3 VERTEXING |
AliAnalysisTaskSEVertexingHF | HF vertexing | ESD/AOD | delta AOD | OK | OK | OK |
| PVG3 HFE | AliAnalysisTaskHFE | Electrons analysis | ESD/+MC | Histograms | OK | ? | ? |
| PWG3 MUON |
AliAnalysisTaskESDMuonFilter | MUON filtering | ESD | AOD+ (adding muons to tracks) | OK | OK | OK |
| PWG3 MUON |
AliAnalysisTaskFromStandardToMuonAOD | MUON AOD |
AOD | new AOD with muons only | OK | ? | ? |
| PWG4 PARTCORR |
AliAnalysisTaskParticleCorrelation (EMCAL, PHOS) + different plugged-in analysis |
Particle correlations | ESD/AOD/MC |
AOD+ (adding pi0, gamma) Histograms |
OK | OK | OK |
| PWG4 JETAN |
AliAnalysisTaskJets | JETAN | ESD/AOD/MC |
AOD+ (reconstructed jets) Histograms |
OK | OK | OK |
| PWG4 GAMMACONV | AliAnalysisTaskGammaConversion | Gamma conversion task | ESD/MC | Histograms | OK | OK | OK |